yolov3学习笔记
基本概念
下采样即图像缩小;将x*x个像素点取均值换算为一个。
上采样即图像放大,利用插值算法。
ground truth即监督学习中数据标注的正确的范围。也就是标准答案的意思。
IOU预测的范围(bounding box)与ground truth的交集/两者并集
bounding box(bbox) 在目标检测中不仅要知道目标的类别还要知道它的位置。在木变检测中常用边界框来描述目标位置。
anchor box目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。(——动手做深度学习)
精确率与召回率实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
P=TP/(TP+FP)
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
R=TP/TP+FN
非极大值抑制简称为NMS算法,思想是搜索局部最大值,抑制极大值。
流程如下:
根据置信度得分进行排序
选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
计算所有边界框的面积
计算置信度最高的边界框与其它候选框的IoU。
删除IoU大于阈值的边界框
重复上述过程,直至边界框列表为空。
**批标准化(batch normalization)**将分散的数据统一的做法,便与神经网络的学习和优化。normalization 预处理, 使得输入的 x 变化范围不会太大, 让输入值经过激励函数的敏感部分。BN实在每个全连接层之间都进行批数据标准化。(作者:

聚类算法
聚类算法是根据样本之间的距离来将他们归为一类的,这个距离不是普通的距离,理论上叫做欧氏距离。
一般面向大量的,同时维度在2个或两个以上的样本群。
1、在样本中随机选择K个点,作为每个类别的初始中心点,这K是自己定的,假如你想将样本分成3个类K就等于3,4个类K就等于4;
2、计算所有样本离这K个初始中心点的距离并分别进行比较,选出其中最近的距离并把这个样本归到这个初始中心点的类别里,即总共划分成K个类别;
3、舍弃原来的初始中心点,在划分好的K个类别里分别计算出新的中心点,使得这些中心点距离他类别里的所有样本的距离之和最小;
4、判断新获得的中心点是否与旧中心点一样,如不一样则回到第2步,重新计算所有样本离这K个新的中心点的距离并进行比较,选出其中最近的距离并归到这个新的中心点的类别里,继续下面的步奏;如一样则完成,即收敛。
残差网络
残差
残差:实际观测值与估计值(拟合值)之间的差。如果回归模型正确则残差可以看做误差的观测值。
理论上,可以训练一个 shallower 网络,然后在这个训练好的 shallower 网络上堆几层 identity mapping(恒等映射) 的层,即输出等于输入的层,构建出一个 deeper 网络。这两个网络(shallower 和 deeper)得到的结果应该是一模一样的.
退化问题
为什么属于随着层数的增多训练集上的效果变差?
原因是随着网络越来越深,训练变得原来越难,网络的优化变得越来越难。理论上,越深的网络,效果应该更好;但实际上,由于训练难度,过深的网络会产生退化问题,效果反而不如相对较浅的网络。而残差网络就可以解决这个问题的,残差网络越深,训练集上的效果会越好。(测试集上的效果可能涉及过拟合问题。过拟合问题指的是测试集上的效果和训练集上的效果之间有差距。)这里要注意到过拟合与退化问题之间的区别
残差块
残差网络是通过加入shortcut connections,变得更容易被优化。包含一个shortcut connection的几层网络被称为一个残差块。shortcut即图中x到 ⨁的箭头。
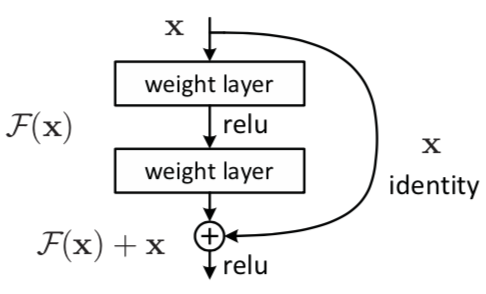
残差块(residual block)
𝑥 表示输入,𝐹(𝑥) 表示残差块在第二层激活函数之前的输出,即 𝐹(𝑥)=𝑊2𝜎(𝑊1𝑥),其中 𝑊1 和 𝑊2 表示第一层和第二层的权重,𝜎 表示 ReLU 激活函数。(这里省略了 bias。)最后残差块的输出是 𝜎(𝐹(𝑥)+𝑥)。
激活函数:上层节点的输出与下层节点的输入之间的函数关系。
常用的激活函数有:sigmoid函数,tanh函数,relu函数(这个比较常用)… …
残差块中的网络可以使全连接层也可以是卷积层。
设第二层网络在激活函数之前的输出为 𝐻(𝑥)。如果在该 2 层网络中,最优的输出就是输入 𝑥,那么对于没有 shortcut connection 的网络,就需要将其优化成 𝐻(𝑥)=𝑥;对于有 shortcut connection 的网络,即残差块,最优输出是 𝑥,则只需要将 𝐹(𝑥)=𝐻(𝑥)−𝑥 优化为 0 即可。后者的优化会比前者简单。这也是残差这一叫法的由来。
上面相当于优化了恒等映射。残差网络可以不是神经网络,用全连接层也可以。
为什么残差网络会work
我们给一个网络不论在中间还是末尾加上一个残差块,并给残差块中的 weights 加上 L2 regularization(weight decay),这样图 1 中 𝐹(𝑥)=0 是很容易的。这种情况下加上一个残差块和不加之前的效果会是一样,所以加上残差块不会使得效果变得差。如果残差块中的隐藏单元学到了一些有用信息,那么它可能比 identity mapping(即 𝐹(𝑥)=0)表现的更好。
边界框回归
对于窗口一般使用四维向量(x,y,w,h) 来表示, 分别表示窗口的中心点坐标和宽高。 对于图 2, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口Ĝ。
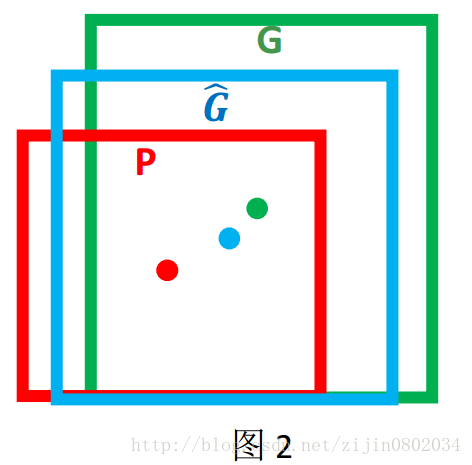
边框回归的目的既是:给定(Px,Py,Pw,Ph)(Px,Py,Pw,Ph)寻找一种映射ff, 使得f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^)f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^) 并且(Gx^,Gy^,Gw^,Gh^)≈(Gx,Gy,Gw,Gh)
边框回归的方法:平移+尺度缩放
yolov1-yolov3
yolov1
检测处理理想
将输入图片划分为S * S的格子(逻辑区域),如果物体的中心坐标落在某个格子中,那么这个格子就负责检测这个物体(包括bounding box的坐标和类别概率)。每个格子预测B个bounding boxes和B个置信度,这个置信度表示这个格子预测的bounding boxes包含物体的可信程度,论文作者将置信度定义为 Pr(Object)* IOU。Pr(Object)的值为0或者1,表示存不存在目标物体。
每一个bounding box包括五个元素,x,y,w,h,confidence。坐标(x,y)表示的是box的中心坐标,并且是相对于格子的边界而言,w和h也是相对于整张图片的宽度和高度而言。置信度预测的值表示预测框和真实框的IOU值。虽然每个格子预测B个bounding box,但是每个格子只预测一组类条件概率,注意这里不是anchor,因为多个bounding box共用了一组class probability(表示的是先验概率)。所以网络架构的最后一层实际预测了B个bouding box和一组类别概率,注意这只是针对于一个格子,所以在不考虑batch size的情况下,实际预测输出长度为S* S*(B*5+C)
训练过程
对于前面所说bounding box,作者也做了一些处理,将bounding box的w,h除以训练图像的宽度和高度(448*448),使其值在0-1之间。至于bouding box的x,y的实际值意义,作者认为不是相对于整张图片的中心坐标值,而是相对于的对应格子坐标左上边界偏移值,所以x,y的值也在0-1之间,这个地方有些难以理解。
通过置信度为每一个各自从B个bounding box中筛选一个最终的bounding box。于是每个各自的坐标为(0+x,0+y),(0+x, 1+y)…….
通过我们设定的置信度阈值使用非极大值抑制方法从这49个bounding box中筛选;还有一种做法就是直接从98个bounding boxes使用非极大值抑制方法筛选。从图片的全局性来考虑,第一种方法更能体现图片的整体性。确定完bounding boxes后,用bounding box坐标值乘以与原图的比例值就可以在原图中框出相应的物体。
yolov2
1.对数据进行批标准化处理。
2.High Resolution Classifier:低分辨率训练分类网络,高分辨率训练检测网络,在两个过程见了一个适应性微调。
3.Convolutional With Anchor Boxes(锚框卷积):作者去掉了YOLOv1的全连接层,使用anchor boxes来预测bounding boxes,同时也去掉了最后池化层使得最后feature maps的分辨率大一些。与YOLOv1不同的是,YOLOv2为每一个bounding box预测一个类条件概率【YOLOv1中B个bounding box共用一个类条件概率】。在YOLOv1中bounding boxes数目为:S* S*(5* B+C),而在YOLOv2中bounding box数目为S * S*B(5+C)。使用anchor box没有使精度提升,提高了召回率。
4.作者采用维度聚类的方法对数据集的真实标签的bounding box进行聚类分析从而确定B的取值。如果用欧式距离来衡量K-means的距离,会使得大的bounding box比小的bounding box产生更大的误差,于是作者调整距离计算公式为:
5.13* 13的feature map可以提供足够信息预测较大的物体,但是对于小物体而言提供的信息仍然不够,所以作者提供了一个passthrough层,利用26*26的feature map来预测小物体(可能是受SSD的启发,不同大小的特征图检测不同大小的物体)。
6.YOLOv2的网络只有卷积层和池化层,所以就可以在训练进行的过程改变feature maps的shape。 为了使得YOLOv2更具鲁棒性,我们让模型能够对不同大小的图片进行训练。在训练过程中,每10个batch就换一组新尺度的图片(这里的新图片指大小不同,图片的其他属性是一样的)。
作者提出了一种将分类数据集和检测数据集联合训练的方法,在训练的过程,我们将这两类数据集混合,当输入的检测数据集时,反向传播全部的误差损失(YOLOv2的loss),当遇到分类数据集时,只反向传播分类误差损失。
yolov3
### 1.边界框预测
YOLOv3中引入一个Objectness score概念,使用logistic regression为每一个bounding box预测一个Objectness score。将预测的bounding boxes中与真实bounding box重叠最大的bounding box的Objectness score赋值为1,如果这个bounding box与真实bounding box重叠值达到设定的阈值0.5,这个bounding box的损失为0,其同一格子里面的其他bounding box只计算置信度损失,忽略坐标损失和类别损失。(可以认为0.5表示预测的边界框已经能很好地标记框出物体,所以不用计算它的损失。每一个格子中的object由一个预测的bounding box预测。既然已经找到了较好地bounding box,所以同一个格子里面的其他bounding box没有必要计算坐标误差和分类误差,只需要计算置信度误差,用来调整置信度,最理想的效果是这些bounding box的置信度值更新为0)。
这里bounding box是指网络模型预测的confidence,bx,by,bw,bh,计算置信度误差时,用真实标签坐标和预测坐标(bx,by,bw,bh)计算IOU,Objectness score相当于Pr(Object),所以最终的置信度计算为IOU*Pr(Object)
2.类别预测
类别预测使用了多标签分类(多分类),没有使用softmax,而是对每一个类各自对立地使用了logistic分类器,用binary cross-entroy loss替代softmax loss,这样能较好地处理标签重叠(包含)关系(例如:女人和人)。
3.交叉尺度(多尺度)预测
YOLOv3预测三种不同尺度的box,每一种尺度预测三个anchor boxes,即NN(3*(4+1+80)),所以最终的输出是3*【NN(3*(4+1+80))】,最前面的3表示三种尺度。3种尺度,3个anchor box,是由聚类数为9决定的,按照一定的顺序(面积从小到大)将这个聚蔟box分配给不同尺度。在YOLOv2中,为了加强对小物体的检测,引入了passthrough层,假设最后提取的feature map的size是1313,passthrough层的作用是将上层2626的feature map和最后层13*13的feature map连接,作为网络最后的输出。
YOLOv3是采用了低分辨率feature map上采用和高分辨率feature map做融合,形成新的feature map层,对新的feature map层单独做预测。这样就是多尺度预测。如果YOLOv3最后一层也是1313的话,那么三个尺度的大小为(1313,2626,5252),第三个尺度只用第二个尺度上采样并做融合。值得说明的是:YOLOv2中的多尺度指输入图像的大小不同,YOLOv3的多尺度是指用不同的分辨率的feature map做预测。
## 参考文献:
什么是批标准化 作者:莫烦
聚类算法 作者:挖数
残差网络 作者:wuliytTaotao
边框回归(Bounding Box Regression)详解 作者:南有乔木NTU
目标检测之YOLO系列-V1至V3改进详解 作者:xd1723138323